Why Kubernetes-ops
We are a big fan of Kubernetes, no matter how you bring up the cluster. Be it on a GKE, EKS, or a Kops cluster. For the last 3 years or so, on AWS we have been using an open source tool called Kops to bring up and maintain our Kubernetes cluster. Initially, AWS didn’t offer a Kubernetes service and when they did come out with one, we felt the Kubernetes life cycle management was still way better with Kops. Enough with our cluster opinions. We’ll have enough opinions on the packages we are about to describe to you =)
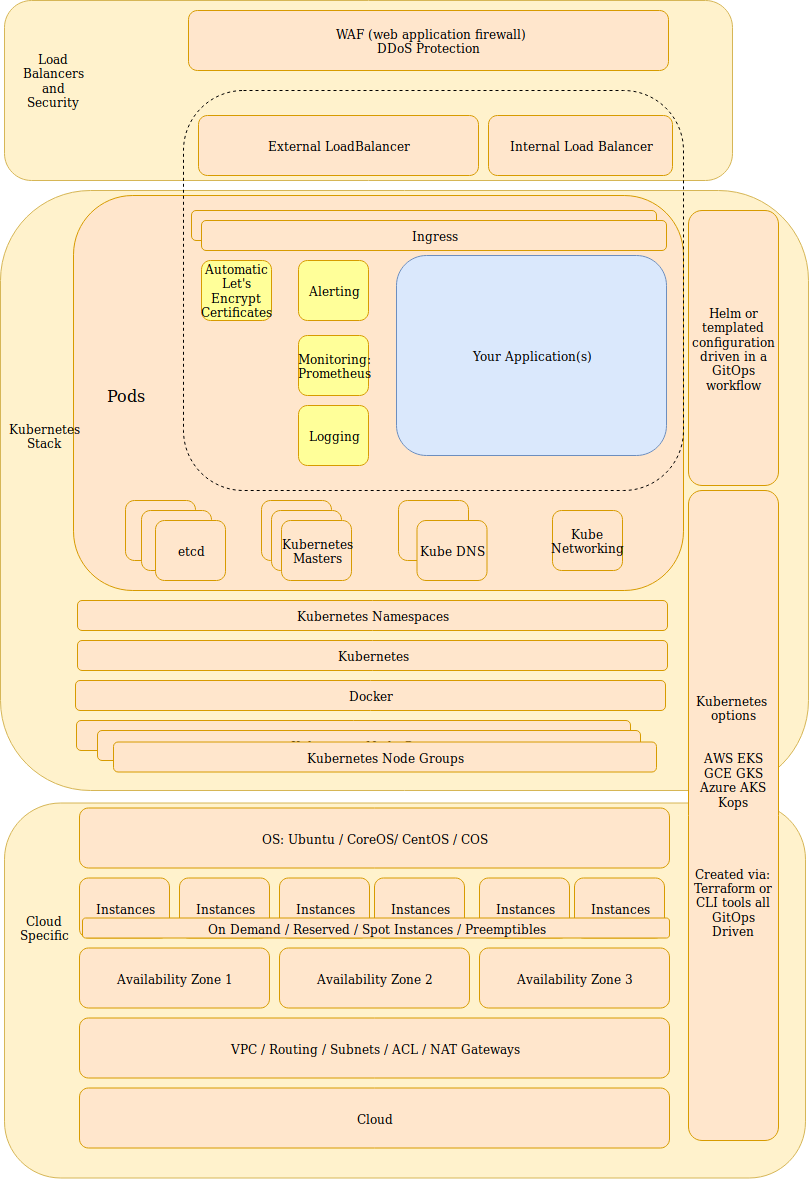
This initial blog will focus on bringing up an entire cluster and managing the life cycle of a Kubernetes cluster on AWS with a complete set of code/config on Github.
What we are presenting here is how we as consultants have brought up Kubernetes cluster for many clients over the years. This represents one of our very opinionated way of creating and managing the life cycle of a Kubernetes cluster and you can use this as a reference implementation. You should be able to follow this all the way through and run a production Kubernetes cluster(s) with this setup. You should also be able to swap out infrastructure pieces out one for another such as kops for GKE or EKS (if we have done our job correctly).
Why is this needed?
- There are infrastructure tools such as Terraform, Puppet, Chef, Salt, etc to help you on an infrastructure level
- There are tools such as Kops, EKS, GKE, AKS, OpenShift, Rancher to help you create a Kubernetes cluster
- There are “Kubernetes package managers” like helm, Operator Hub, etc that curate software packages for you to use
- However, there is not a tool/package or a reference implementation that tells me how to use all of these things together and helps me maintain it via the community. That is where the power lies with Kubernetes. Infrastructure is common and repeated over and over again by all of us. Why should we all take care of individual snowflakes when most of our infrastructure is mostly the same?
- Even with all of these wonderful open source packages which do most of the hard work for us, there is still the part where we have to integrate it into our cluster and run time environment. This is where we are trying to make a difference. We are trying to integrate the pieces for you and boiling it down to knobs and switches you want to change and ensuring it works release after release.
- As a consultant, a lot of my time is spent, selecting the package to use. This surprisingly takes a long time. Since Kubernetes is such a new ecosystem, there are a lot of new and unheard of software for it. This means, you have to keep up with this ecosystem or else you won’t know what is good and what is bad or the trade offs with it. We are currating package that we have worked with and used in production to give you the operational know how.
- As a consultant, a lot of my time is spent, integrating each package into the larger ecosystem. This again surprisingly takes a long time. We are trying help everyone else out by doing the work and maintaining the ecosystem for everyone. This package takes on the bold task of trying to curate an entire stack for you as building blocks. Swap out each piece as you like and they should all still work.
We stress the “managing the life cycle” of the Kubernetes cluster. Most tutorial out there handles mainly the creation of a cluster and how easy it is. The part that falls apart for most clients I work with is what do you do after that? Cluster creation is about 20% of the entire life cycle (if that). The more pressing questions we want to answer are: How do you upgrade this cluster, change it to your evolving needs, and general maintenance of the cluster.
We think of Kubernetes as the infrastructure plumbing. We also think of these items as additional plumbing that most people would end up installing anyways. Just like how kops/gke put all of the Kubernetes part together for us, why isn’t there something that also puts these other essential pieces together for us?
While it is not hard to get these pieces working, it takes some time to make them all working together and make sure they are working together after updates happens. Why should you have to take care of that, just like you don’t want or should have to think much about how the next Kubernetes upgrade will go. This allows you to leave the boring infrastructure part to this package and devote more time to your application.
There is no magic to this. This is all done with open source pieces in the GitHub repo we maintain. These packages are tested to work together. Use all or some depending on your needs.
This GitHub repo is trying to represent a sane way of keeping your infrastructure as code and as a fully working implementation of all of these pieces working together.
Why all this complexity? There are plenty of demo apps and tutorials it there to get started. However, I have never found those to be a good place to turn into a real production setup. So this repository is a lot more complex and it takes some time to familiarize yourself with it but going to a real production Kubernetes infrastructure, this is what I have found that I had to create for countless number of clients.
If you wanted a first step Kubernetes tutorial this is not it. This is meant for people that has already played with Kubernetes and maybe even have done a poc on it and now you want a production setup but wanted to know what are the best practices to run this in production and how can I do it and seeing my repository to support a gitops methodology.
Also remember that most demo goes through how to do the initial setup only and does not talk about the entire lifecycle if the software. Initial setup is probably about 20 percent of the life of the application. Each component with need to be updated or changed to meet your changing needs over time. You need a sane way of doing these changes, especially in production. So this reference implementation also embodies this idea.
Here is the repository on how to get started: https://github.com/ManagedKube/kubernetes-ops/blob/master/docs/the-easier-way.md
Contact me if you have any questions about this or want to chat, happy to start a dialog or help out: blogs@managedkube.com {::nomarkdown}
Learn more about integrating Kubernetes apps
{:/nomarkdown}
Why | Kubernetes-ops