GCP Scaling and Quota Issues Troubleshooting
GKE Scaling issues
Small clusters usually runs fine and the problems usually happens when you start to scale up. Here are some issues you can encounter and how to solve them.
Maxed out your quotas
If you have the cluster autoscaler option enabled, it will help you turn on more nodes when you need them like when you start to deploy out more pods and it can’t be scheduled anywhere unless a new node is created and it will also help you to turn off the nodes when your workload goes down. It is pretty great.
However, you can run into some problems.
Let’s say you scaled out some node and a bunch of pods are sitting in the pending state:
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
echoserver-5fd79c78b7-2dwvt 1/1 Running 0 18m 10.20.79.8 gke-dev-pool-2-df7ac3e2-hlnm <none> <none>
echoserver-5fd79c78b7-2sbsg 0/1 Pending 0 18m <none> <none> <none> <none>
echoserver-5fd79c78b7-4ssxm 1/1 Running 0 22m 10.20.74.2 gke-dev-pool-2-e22b3b39-bh57 <none> <none>
echoserver-5fd79c78b7-5d5rp 1/1 Running 0 18m 10.20.80.6 gke-dev-pool-2-df7ac3e2-w2rk <none> <none>
echoserver-5fd79c78b7-5ll9p 0/1 Pending 0 18m <none> <none> <none> <none>
echoserver-5fd79c78b7-5rzwq 0/1 Pending 0 18m <none> <none> <none> <none>
echoserver-5fd79c78b7-5srbz 1/1 Running 0 21m 10.20.74.8 gke-dev-pool-2-e22b3b39-bh57 <none> <none>
echoserver-5fd79c78b7-5vpgv 1/1 Running 0 21m 10.20.74.7 gke-dev-pool-2-e22b3b39-bh57 <none> <none>
echoserver-5fd79c78b7-6l48m 1/1 Running 0 18m 10.20.81.6 gke-dev-pool-2-df7ac3e2-k0vh <none> <none>
echoserver-5fd79c78b7-6trhh 1/1 Running 0 18m 10.20.80.3 gke-dev-pool-2-df7ac3e2-w2rk <none> <none>
echoserver-5fd79c78b7-6wch7 1/1 Running 0 18m 10.20.79.6 gke-dev-pool-2-df7ac3e2-hlnm <none> <none>
echoserver-5fd79c78b7-6z4hf 0/1 Pending 0 18m <none> <none> <none> <none>
echoserver-5fd79c78b7-6zb68 1/1 Running 0 20m 10.20.78.2 gke-dev-pool-2-bc964768-zjps <none> <none>
echoserver-5fd79c78b7-7lmdv 1/1 Running 0 22m 10.20.73.7 gke-dev-pool-2-df7ac3e2-sn06 <none> <none>
echoserver-5fd79c78b7-7m2d6 1/1 Running 0 22m 10.20.73.5 gke-dev-pool-2-df7ac3e2-sn06 <none> <none>
echoserver-5fd79c78b7-7md9r 0/1 Pending 0 18m <none> <none> <none> <none>
echoserver-5fd79c78b7-8bt2s 0/1 Pending 0 18m <none> <none> <none> <none>
You checked your max setting on the node pool and they are way above the number of nodes you have.
You describe the pod to see what is going on:
kubectl describe pod echoserver-5fd79c78b7-2sbsg
Name: echoserver-5fd79c78b7-2sbsg
Namespace: default
Priority: 0
Node: <none>
...
...
...
Normal TriggeredScaleUp 3m37s cluster-autoscaler pod triggered scale-up: [{https://content.googleapis.com/compute/v1/projects/managedkube/zones/us-central1-a/instanceGroups/gke-dev-pool-1-7de6dd72-grp 3->10 (max: 50)} {https://content.googleapis.com/compute/v1/projects/managedkube/zones/us-central1-b/instanceGroups/gke-dev-pool-1-8d292ef0-grp 3->10 (max: 50)}]
In the Events section you do see the cluster-autoscaler returning an event saying it is scaling up the nodes. You wait for a little while and nothing happens.
The next thing you should look at is the Events for the entire system:
kubectl get events --all-namespaces
kube-system 3m34s Warning ScaleUpFailed ConfigMap Failed adding 1 nodes to group https://content.googleapis.com/compute/v1/projects/managedkube/zones/us-central1-f/instanceGroups/gke-dev-pool-1-cf69e07c-grp due to OutOfResource.QUOTA_EXCEEDED; source errors: Instance 'gke-dev-pool-1-cf69e07c-4chc' creation failed: Quota 'CPUS' exceeded. Limit: 100.0 in region us-central1.
I’ve cherry picked the event giving the cause of this non-scale up but in this case it is running into a Quota issue.
This is indicating that the quota in GCP is set to 100 but you have requested more than that. Now you have to go into the GCP console and increase the limit:
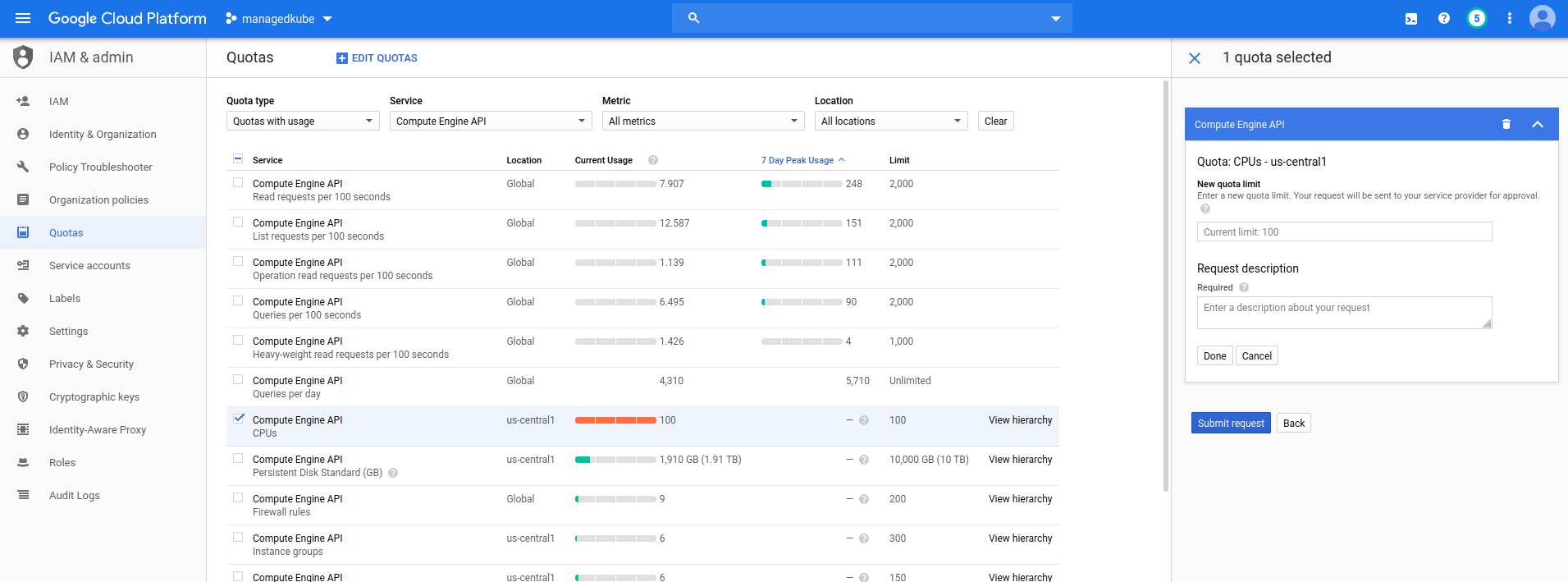
You will have to submit a request and wait for a bit until they increase it.
Once that limit has been increased, the GKE system will do it’s thing and start turning on more nodes.
Out of IP addresses
Continuing with out example, we then started to see more nodes come online then it stops scaling out with the same symtoms as the previous Quota issue. Once again, we perform the same troubleshooting steps as above and once again the kubectl get events output gives us the clue on what is wrong:
kubectl get events --all-namespaces
...
...
kube-system 16m Warning ScaleUpFailed ConfigMap Failed adding 37 nodes to group https://content.googleapis.com/compute/v1/projects/managedkube/zones/us-central1-a/instanceGroups/gke-dev-pool-1-7de6dd72-grp due to Other.OTHER; source errors: Instance 'gke-dev-pool-1-7de6dd72-qdp0' creation failed: IP space of 'projects/managedkube/regions/us-central1/subnetworks/dev-gke-private-dev-gke-pods-b0342e647fe7893e' is exhausted...
...
...
its a long output and I have cherry picked the important log line.
This is telling us that it has exhausted the IP space usage.
We can verify this by looking at the GCP console. Lets look at the compute nodes and in what subnets they are on. From the log line we can see that it is pointing to the IP Space of projects/managedkube/regions/us-central1/subnetworks/dev-gke-private-dev. That looks like it cooresponds to the subnetwork of dev-gke-private-dev-pods. It also looks like it assigns a CIDR of a 10.20.83.0/24 to each node.
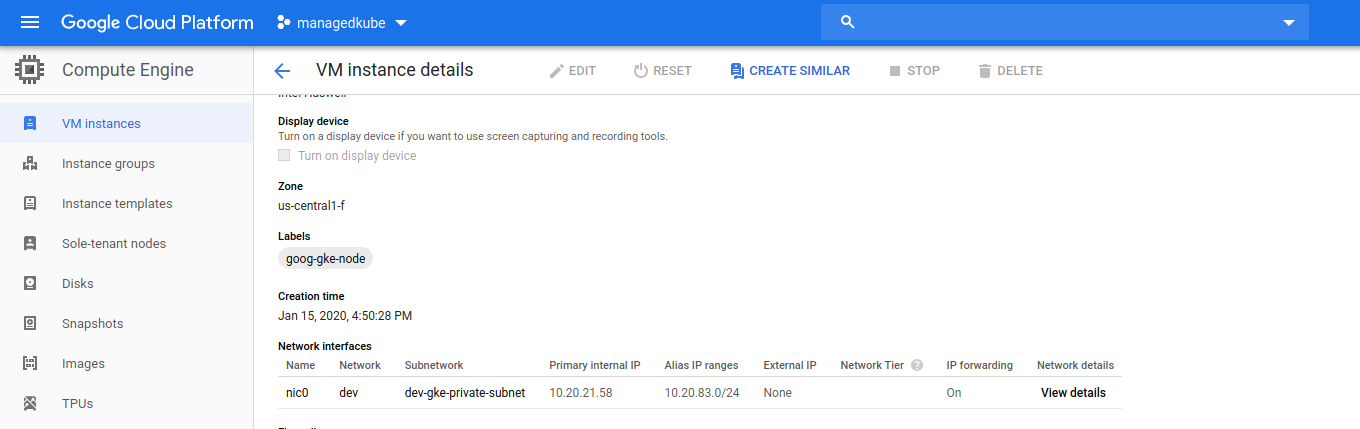
Let’s look at this subnet by clicking on the link of the subnet name:
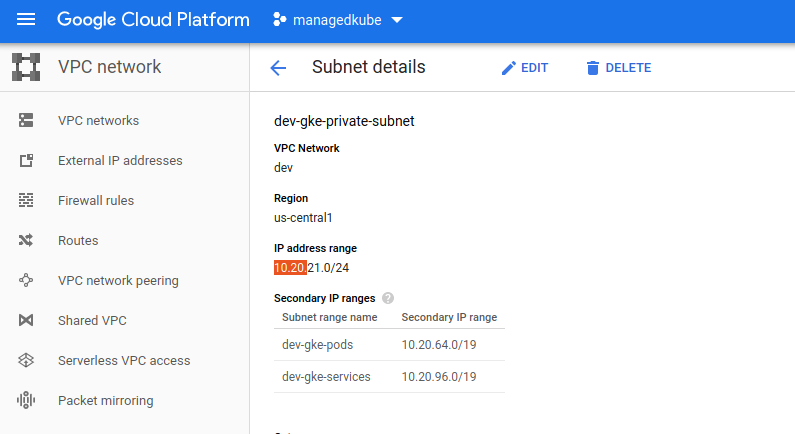
The dev-gke-pods subnet range is: 10.20.64.0/19
With a range like that and we are using a /24 CIDR block that would give us a total of 32 blocks. A co-worker sent me this nice CIDR cheat sheet https://www.aelius.com/njh/subnet_sheet.html.
So it looks like our subnet is too small. It will not be able to assign out any more IP blocks out to new nodes.
Contact me if you have any questions about this or want to chat, happy to start a dialog or help out: blogs@managedkube.com {::nomarkdown}
Learn more about integrating Kubernetes apps
{:/nomarkdown}
GCP | Scaling | and | Quota | Issues | Troubleshooting